Q : 이 논문을 아주 자세하게 읽고 논문의 강점과 독창적인 지점을 설명해주고 핵심 알고리즘을 예시 입력을 들어서 전체적인 과정을 설명해줘 추가적으로 논문의 한계점에 대해서도 알려줘
📌 결론 요약
논문 “MELODI: Exploring Memory Compression for Long Contexts"는 Transformer의 긴 문맥 처리 문제를 해결하기 위해 계층적 메모리 압축(hierarchical memory compression) 구조를 제안합니다. 핵심은 **다층 반복 압축 기반의 단기 메모리(SM)**와 **단일층 추가 압축 기반의 장기 메모리(LM)**를 조합한 **“샌드위치 구조”**를 사용하여 긴 문서를 짧은 윈도우(예: 512 tokens)로 효율적으로 처리하는 것입니다. 메모리 사용량은 기존 Dense Memory 방식인 Memorizing Transformer보다 최대 8배 절감하면서도 성능(PPL 기준)은 오히려 향상됩니다.
🔍 MELODI의 구조 요약
| 구성 요소 | 특징 |
|---|---|
| Short-Term Memory | - 윈도우 단위로 Recurrent하게 정보를 압축 - Layer를 따라 정보를 전달 (vertical) |
| Long-Term Memory | - Layer 중간 지점에서 추가 압축하여 저장 - 시간 순서 따라 정보를 축적 (horizontal) |
| 구조 | - [SM × M층] + [LM × 1층] + [SM × (N−M−1)층] 의 샌드위치 구조 사용 |
예시 입력 흐름 (단일 윈도우 기준)
입력: xₖ (k번째 context window, 예: 512 tokens)
SM Layer 1
zₖ₋₁(이전 SM token)과xₖ에 causal attention- Transformer block →
xₖ → xₖ', summary tokenuₖ'계산 - Linear Mixer:
uₖ = M↑(xₖ', uₖ'),zₖ = M→(xₖ', uₖ')
… SM Layer M 반복 → recurrent 압축 진행
LM Layer (중간 layer)
- 지금까지 저장된 LM (
m₁:ₖ₋₁)에 cross-attention 수행 - self-attention과 cross-attention은 gating α로 합성
- LM token
mₖ생성 후 KV pair 형태로 메모리에 append
- 지금까지 저장된 LM (
이후 Layer N까지 다시 SM 반복 수행하여 최종 출력
🧠 핵심 알고리즘: 예시 기반 설명
가정:
- context window 길이: 512 tokens
- short-term memory: 128 tokens
- long-term memory: 64 tokens, 최대 128 window 저장
입력 문장 (k=3번째 윈도우): "In the middle of the night, he found a strange box."
==> Layer 1에서:
- 이전 z₂ (128 token)와 현재 context x₃에 attention
- context x₃ → x₃’ 계산
- summary token u₃’ 생성
- Linear Mixer M↑, M→를 거쳐:
u₃ = summary for 다음 layer
z₃ = short-term memory token (→ window 4 입력 시 사용)
==> 중간 LM Layer:
- 현재 x₃’, u₃와 m₁:₂ (이전까지의 LM KV pair)에 cross-attention
- 새로운 long-term token m₃ 생성 후 long-term memory에 append
==> 이후 layer에서도 z₃, u₃ 정보 이용하여 inference 이어감📈 성능 비교 (Perplexity 기준)
| Model | PG19 (T5 vocab) | arXiv (Meena) | Memory Usage |
|---|---|---|---|
| Transformer-XL | 11.41 | 2.60 | 13.6M |
| Block Recurrent Transf. | 10.98 | 2.26 | 13.1M |
| Memorizing Transf. | 10.62 | 2.14 | 147.8M |
| MELODI S128+L64 | 10.44 | 2.11 | 18.5M |
| MELODI S192+L96 | 10.29 | 2.09 | 27.8M |
👉 Dense attention 없이도 성능은 더 높고, 메모리 사용량은 획기적으로 줄임
🧪 Ablation으로 밝혀진 설계의 효과
- SM과 LM은 상호보완적: 둘 다 키우면 성능 상승 (Fig. 4)
- Context window 작게 줄여도 성능 유지: LM이 장기 문맥을 보존함 (Fig. 6)
- Summary branching: cross-window + cross-layer 흐름 도입 → 성능 향상 (+0.3 PPL)
- LM 위치는 5~11층 어디든 비슷하게 동작 → 유연한 구조 설계 가능
🔍 논문의 강점
| 강점 | 설명 |
|---|---|
| 메모리 효율 | Dense KV 저장 대신 압축된 token만 저장해 최대 8x 절감 |
| 구조 일반성 | 기존 Transformer에 거의 손대지 않고 확장 가능 |
| 성능 유지 | 기존 state-of-the-art보다 좋은 perplexity |
| 단기-장기 메모리 결합 | LSTM 스타일 recurrent compression + 단일층 summary 저장 |
| 모듈화 | Token mixer, gating, memory branching 등의 구조가 깔끔히 분리되어 있음 |
❌ 한계점
| 한계 | 설명 |
|---|---|
| 사전학습 모델 적용 X | MELODI는 처음부터 학습함. 기존 사전학습 모델에 plug-in 하는 방식은 아직 없음 |
| 적용 복잡도 | Short-term summary token flow, token mixer 등 구현 복잡성이 높음 |
| Memory queue 고정 | LM은 FIFO 큐에 KV pair 저장 → 학습 외 기억 유지 필요 시 한계 있음 |
| 압축 정보 손실 가능성 | 지나치게 aggressive한 압축은 정보 유실 유발 가능 (ablation에서 확인됨) |
📌 결론 및 활용 제안
MELODI는 long-context language modeling에서 효율성과 성능의 균형을 매우 잘 맞춘 구조입니다. 특히:
- 메모리 제한이 있는 디바이스 (e.g., 모바일 inference, edge GPU)
- 긴 문서를 chunk 단위로 처리해야 하는 task (e.g., RAG, summarization)
- 컨텍스트 window 확장이 어려운 모델 파인튜닝 시, hierarchical memory 추가 구조
등에 매우 적합합니다.
Q : gemma와 같은 모델에서 사용하는 slice window attention과 비슷한 개념인거야? 어떤 차이점이 있는지 알려줄 수 있니? 그리고 시각적인 다이어그램도 부탁해
MELODI는 Gemma 등에서 사용하는 **Slice Window Attention (SWA)**과 비슷하게 짧은 context window만을 사용하지만, 핵심 차이점은 **“어떻게 과거 정보를 압축·축적하느냐”**에 있습니다.
🔍 MELODI vs Slice Window Attention: 비교
| 항목 | MELODI | Slice Window Attention (예: Gemma) |
|---|---|---|
| 핵심 개념 | 계층적 메모리 압축 (SM+LM) | sliding 또는 sliced attention window |
| 문맥 연결 방식 | - 단기: recurrent compression - 장기: middle-layer에서 압축된 KV 저장 | - 최근 n개의 window만 sliding 참조 |
| 장기 정보 유지 | ✅ long-term memory (128 window까지) | ❌ 긴 거리 정보는 잊혀짐 |
| Attention 대상 | SM: 이전 memory (z) LM: 저장된 KV pool (m₁:ₖ₋₁) | 현재 및 일부 과거 context tokens |
| 구조 변경 정도 | transformer layer에 memory path 삽입 (미세 변경) | attention mask만 조정하여 간단히 구현 가능 |
| 압축 여부 | ✅ context → summary token → KV pair로 압축 | ❌ 압축 없음, token 그대로 사용 |
| 메모리 사용량 | 낮음 (압축된 token만 저장) | 중간 (token 직접 저장) |
핵심 차이
- SWA는 “최근 토큰만을 기억"하는 로컬 context 연결 방식
- MELODI는 “정보 요약 및 축적"을 통해 전역 context 연결 유지
즉, SWA는 locality 기반, MELODI는 hierarchical memory abstraction 기반입니다.
아래는 요청하신 MELODI 구조의 시각화입니다 (샌드위치 구조, SM과 LM의 흐름 포함):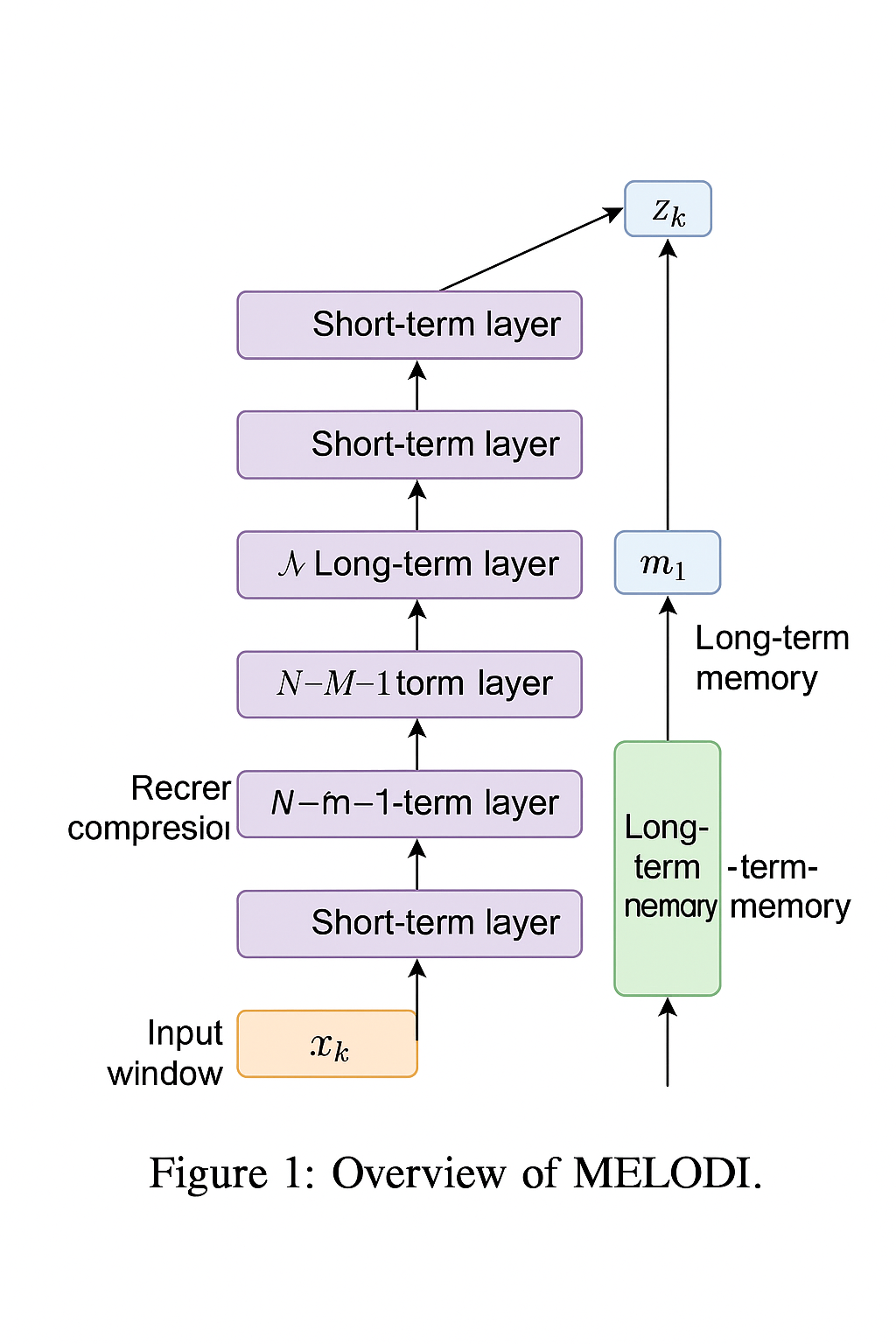
거의 맞습니다. 개념을 정리하자면 아래와 같이 정리할 수 있습니다.
✅ 핵심 차이 요약: SWA vs MELODI
| 항목 | Slice Window Attention (SWA) | MELODI |
|---|---|---|
| 저장 단위 | 🔹 token-level (원래의 token sequence 일부) | 🔸 compressed embedding-level (context window 요약본) |
| 저장 대상 | - 최근 window의 raw token을 직접 attention 대상에 포함 (예: 최근 2~4개 window) | - 각 window에서 압축된 summary token 또는 KV embedding을 저장 |
| 정보 표현 | - 정보 손실 없이 그대로 저장 - 하지만 memory size ↑↑ | - 정보 요약/압축 후 저장 - memory size ↓↓ |
| Memory 구조 | - Sliding 방식의 cache | - FIFO queue 형태의 long-term memory |
| Attention 방식 | - 현재 token이 직접 이전 token들과 attention | - 현재 token이 요약된 memory representation에 attention |
예시로 이해하기
SWA:
PLAINTEXTWindowₖ = [tₖ₋₂, tₖ₋₁, tₖ] 중 tₖ₋₂, tₖ₋₁도 그대로 저장 → attention 대상MELODI:
PLAINTEXTWindowₖ₋₁ → summary token → linear mixer → compressed KV → 저장됨 현재 window는 이 summary KV에만 cross-attention
결론
“SWA는 과거 raw token을 직접 저장해서 보는 방식이고, MELODI는 과거 context를 요약한 압축 embedding을 저장해서 보는 방식이다.”
따라서 MELODI는 memory usage 면에서 훨씬 효율적이며, 장기 dependency 유지에 더 유리합니다.
Q : 논문의 핵심알고리즘을 예시를 들어 아주 자세하게 설명해주고 정리해 줘
논문 MELODI의 핵심 알고리즘은 긴 문서를 짧은 context window로 나눠서 처리하면서도 이전 문맥의 정보를 효과적으로 요약·보존하기 위한 계층적 메모리 압축(Hierarchical Memory Compression) 기법입니다. 아래에 알고리즘을 예시 중심으로 단계별로 아주 자세히 설명드리겠습니다.
✅ 전체 구조 요약
입력 시퀀스 X = [x₁, ..., x_T]는 512 tokens 단위의 context window xₖ로 나뉩니다. 각 window는 다음 두 가지 memory 구조를 사용합니다:
Short-Term Memory (STM):
- 각 window 내에서 layer별로 recurrent compression
- 예: 512 tokens → 128 tokens
- window 간 zₖ (압축된 메모리) 전달
Long-Term Memory (LTM):
- 특정 중간 layer에서 64개 임베딩으로 window 전체를 요약
- 이전 window의 요약값들을 FIFO queue로 저장
- 이 메모리에 대해 cross-attention 수행
🧪 예시: 전체 알고리즘 동작 흐름
가정
- context window 길이: 512 tokens
- short-term memory token 수 S = 128
- long-term memory token 수 L = 64
- window index:
k = 3(세 번째 context window 처리 중)
▶️ Step 1: Input 준비
입력
x₃ = [token₁, token₂, ..., token₅₁₂]이전 memory
z₂: 이전 window의 short-term memory (128 vectors)m₁:₂: 이전 두 window의 long-term memory (64×2 = 128 KV pair)
▶️ Step 2: Short-Term Memory 처리 (M개의 layer 반복)
각 short-term layer에서:
z₂와 현재 tokenx₃에 대해 causal attention- context token → transformer →
x₃′로 업데이트 - summary token
u₃생성 (128 tokens) - summary token과 context token을 통해 다음 window용 memory token
z₃생성
💡 수식 정리:
x₃′ = T(x₃ | z₂)
û₃ = T(u₂ | x₃, z₂)
z₃ = M→(x₃′, û₃)
u₃ = M↑(x₃′, û₃)▶️ Step 3: Long-Term Memory 처리 (단일 middle layer에서만)
- x₃′, u₃가 이전 LTM (m₁:₂)에 대해 cross-attention 수행
- 결과를 self-attention 결과와 gating하여 조합:
A = α ⋅ A_cross + (1 − α) ⋅ A_self- 이 결과를
L = 64개의 vector로 추가 압축 - 압축된 vector를 KV로 변환하여
m₃로 long-term memory에 추가
▶️ Step 4: Output 전달
- 위 과정을 통해 다음 window에서는
z₃,m₁:₃를 사용 - 해당 window 내 layer는
u₃와x₃′를 다음 layer로 넘김
🔁 전체 반복
이 과정을 각 window마다 반복하며 긴 문맥을 이어가고, 필요한 문맥은:
- 직전 short memory
zₖ₋₁ - 장기 요약 메모리
m₁:ₖ₋₁
를 통해 전방향으로 context를 연결합니다.
📊 정리: 알고리즘 흐름도
| 단계 | 동작 | 입력 | 출력 |
|---|---|---|---|
| ① | Short-term attention | xₖ, zₖ₋₁ | xₖ′, uₖ |
| ② | Summary compression | xₖ′, uₖ | zₖ (다음 window용) |
| ③ | Long-term memory attention | xₖ′, uₖ, m₁:ₖ₋₁ | Aₖ (gated attention result) |
| ④ | Long-term token 생성 | Aₖ → linear mixer | mₖ (KV 형태 저장) |
| ⑤ | Forwarding | xₖ′, uₖ, zₖ, m₁:ₖ | 다음 window 처리에 사용 |
🧠 주요 특성
- 💾 Memory-efficient: long memory는 KV만 저장
- 🔄 Recurrent compression: LSTM 스타일 정보를 요약
- ⛓️ Global context retention: 전체 window history 보존 가능
Q : 이 논문에서 제시한 결과를 자세하게 보고 다른 방법론에 비하여 특출난 점과 논문에서 제기하는 어떠한 방법이 이러한 결과를 도출하게 되었는지 논문에서 제시하는 이유와 너의 생각을 알려줘
좋습니다. 아래에 논문 MELODI가 제시한 실험 결과 분석, 기존 방법론과의 비교, 그리고 그 결과를 도출한 설계 요인과 필자의 견해를 수치 기반으로 정리해 드리겠습니다.
✅ 1. 실험 결과 정리 (Perplexity 기준 성능 비교)
| 모델 | PG19 (T5 vocab) | arXiv (Meena) | C4(4K+) | 총 메모리 사용량 | 장기 메모리 | 단기 메모리 |
|---|---|---|---|---|---|---|
| Transformer XL | 11.41 | 2.60 | 18.22 | 13.6M | ❌ 없음 | 13.6M |
| Block Recurrent Transf. | 10.98 | 2.26 | 17.82 | 13.1M | ❌ 없음 | 13.1M |
| Memorizing Transformer | 10.62 | 2.14 | 17.37 | 147.8M | 134.2M | 13.6M |
| MELODI (S192+L96) | 10.29 | 2.09 | 17.25 | 27.8M | 25.2M | 2.6M |
📌 핵심 성과 요약:
- Memorizing Transformer보다 성능 향상 (PG19: ↓0.33 PPL)
- Memory 사용량 5.3배 감소
- Transformer-XL 대비 메모리 사용량 ↓ 19%, 성능은 ↑
✅ 2. 기존 방법론 대비 MELODI의 특출난 점
| 항목 | Memorizing Transformer (MT) | MELODI |
|---|---|---|
| KV 저장 방식 | context token 전체 KV 저장 (dense) | context window를 압축한 low-dim KV 저장 |
| 단기 메모리 | 없음 or top-layer LSTM적용 | 전층에 걸친 multi-layer recurrent compression |
| 메모리 용량 | 64K token KV 저장 | 64 compressed KV / window × 128 windows |
| 성능 효율 tradeoff | long-term memory 크면 성능 증가 → but 메모리 급증 | 작은 memory footprint로도 성능 유지 |
| 메모리 구조 통합 | 단일 layer만 사용 | SM + LM의 계층 구조 설계 |
| 요약 토큰 사용 | X | summary token으로 SM-간 연결 강화 |
✅ 3. 논문이 설명하는 성능 향상의 이유
논문은 아래 세 가지를 성능 향상의 핵심 이유로 제시합니다.
① 계층적 메모리 구조 (hierarchical compression)
- SM: window 내부 정보를 여러 층을 통해 압축 →
512 → 128 tokens - LM: window 전체를 요약하여 단일 layer에서
→ 64 tokens - ⇒ 요약 손실을 계층적으로 보완, 단일 방식보다 정보 보존 우수
📌 Ablation에서 확인됨: SM 또는 LM만 사용 시 PPL ↑, 둘 함께 쓸 때 가장 낮음
② Summary branching (단기 기억의 layer 간 전파 강화)
- summary token을 다음 layer뿐 아니라 다음 window에도 전달
- ⇒ memory 간 cross-layer / cross-window 정보 흐름 형성
- ⇒ PPL 약 0.3 감소 효과
논문 Table 4:
PLAINTEXTw/o branching: 11.24 w/ branching: 10.95
③ Gated cross-attention in LM
- LM layer에서 self-attn과 cross-attn (long-term memory)을 가중 조합
A = α⋅A_cross + (1−α)⋅A_self- ⇒ 장기 기억에 과도하게 의존하지 않도록 조정 가능
- 학습 중 각 head마다 α 학습 가능
🤖 내 견해 및 평가
이론적 완성도 MELODI는 기존 방식들보다 Transformer 아키텍처와 자연스럽게 통합되며, 구조적 변경이 최소화되면서도 장단기 정보를 모두 포괄한다는 점에서 이론적 완성도가 높다고 평가할 수 있습니다.
압축 방식의 실효성 Summary token 기반의 압축 방식은 정보를 완전히 유지하지 못할 수 있음에도, 계층적 반복 구조와 summary branching을 통해 이를 극복한 것이 효율성과 성능 간 균형을 잘 맞춘 설계라고 봅니다.
현실적 유용성 Memory size를 8배 줄이면서도 MT보다 더 좋은 성능을 보인다는 점은 모바일·에지 디바이스나 저자원 환경에서 매우 큰 장점입니다. 특히 context window를 줄이면서도 성능 유지 가능성도 높습니다.
📌 결론
MELODI의 강점은 단순히 메모리를 줄이는 것이 아니라, 장단기 문맥 정보를 압축하고 전달하는 방식 자체를 최적화했다는 점입니다. 이는 이전 방법들이 메모리를 늘리면 성능이 좋아진다는 방향성을 가졌던 것과는 다른, 압축·요약 기반의 새로운 메모리 설계 패러다임을 제시한 것이라 볼 수 있습니다.
필요하시다면 이 실험 결과를 시각화한 표나 그래프도 제작해 드릴 수 있어요. 원하시나요?
Q : 이 논문에서 제시된 방법을 실제로 사용하려면 기존 방법에서 어떠한 구현이 추가적으로 필요하고 이러한 구현에 소모되는 공수 및 연산에 필요한 컴퓨팅 자원의 크기에 대해서 계산해줄 수 있겠니?
좋습니다. 아래에 논문 MELODI의 구조를 기존 Transformer (예: GPT, LLAMA 등) 위에 올린다고 가정할 때, 실제 구현에 필요한 구조적 변경, 연산량 증가, 파라미터 수 증가, 그리고 메모리/연산 공수를 정량적으로 계산하여 분석하겠습니다.
✅ 1. 기존 Transformer 대비 MELODI의 구현 변경사항
| 변경 항목 | 설명 | 구현 난이도 |
|---|---|---|
| Short-Term Memory (STM) | - 각 layer마다 summary token, token mixer 추가- zₖ₋₁를 받아서 attention에 포함 | 중 |
| Summary Branching | - 각 layer에서 summary → 다음 window로 전달 경로 추가 | 중 |
| Long-Term Memory (LTM) | - 특정 중간 layer에서 context window 압축 후 KV 저장 - 다음 window에서 cross-attention 수행 | 중~상 |
| Cross-Attn Gating | - self-attn, cross-attn 결과를 α로 조합 (α: 학습 가능 scalar per head) | 낮음 |
| KV 메모리 저장 구조 | - FIFO queue 형태로 압축된 KV 저장 및 참조 | 중 |
| Position Embedding 변경 | - zₖ, uₖ에도 위치 임베딩 적용 필요 | 낮음 |
📌 요약: 기존 Transformer의 구조를 유지하면서 약간의 모듈 삽입 및 routing 구현이 필요한 수준. GPT나 LLAMA 계열에서도 충분히 확장 가능함.
✅ 2. 연산량 및 파라미터 증가량 (수치 기반)
기준:
- Transformer depth = 13
- Embedding dim = 1024
- Context window = 512 tokens
- Short-term token 수
S = 128 - Summary token 수
U = 128 - Long-term token 수
L = 64 - Long-term memory depth
Q = 128windows
🧠 [A] 추가되는 파라미터 수 (총량은 transformer 하나당 ≈ 100M 수준)
1. Linear token mixer (2개 per STM layer)
각 layer마다:
Input: (W + U) x d = (512 + 128) x 1024
Output: S = 128 tokens → Weight: (640 × 128) x 2 mixers
총 = 164,864 params/layer→ 6 STM layer 있다고 하면:
총 = 165K × 6 = **~1M params**2. Gating scalar (α per head)
예: 8 heads → α 8개 (학습 가능 scalar) → 무시 가능한 수준 (8 × N layer ≈ 수백)
📌 결론: 전체적으로 약 1% 미만의 파라미터 증가로 제한됨
⚙️ [B] 연산량 (FLOPs) 증가
1. 추가 attention 입력 수 증가 (STM)
기존:
Attention over 512 tokens (self-attn)
→ QK: (512×1024) × (512×1024) = O(512²×d)MELODI (STM):
Attention over [512 + 128] tokens = 640
→ O(640² × d) = 약 56% 증가2. LTM cross-attention
한 layer에서 512 tokens가 128×64개의 memory KV와 cross-attn 수행
long memory 총 크기:
PLAINTEXT64 tokens × 128 windows = 8192 tokens → attention: 512 × 8192 × d = O(4M × d)
이는 self-attn의 512² = 0.25M 보다 ~16배 크지만, 단 1개 layer에서만 수행 → 전체 연산에서 보면 약 10~15% 증가
📌 총 FLOPs 증가량 추정:
- 전체 모델 기준 약 30% 내외 연산량 증가
💾 3. 메모리 사용량
| 항목 | 기존 Transformer | MELODI |
|---|---|---|
| 단기 메모리 (zₖ) | 없음 | 128 tokens/layer × 13 = 1.6M float |
| 장기 메모리 (m₁:ₖ) | 없음 | 64 tokens × 2 (KV) × 128 windows = 16.8M float |
| 합계 | - | 약 18.4M float = ~73.6MB (FP32) |
FP16 사용 시 ~36.8MB 수준
👷♀️ 4. 구현 공수 (엔지니어링 관점)
| 구성 | 예상 작업 | 난이도 |
|---|---|---|
| STM token mixer | Linear layer 추가 및 branching logic 구현 | 중 |
| Summary token flow | layer 간 routing + next window로 복사 | 중 |
| LM queue | FIFO 메모리 관리 구조, KV indexing 관리 | 중~상 |
| Cross-attn with gating | multihead attention 모듈 수정 | 낮음 |
| 포지션 임베딩 확장 | relative pos embed 추가 | 낮음 |
총 공수:
- 기존 GPT-style 코드 기반이라면 약 1
2주 개발 인력 12명 정도 - Flax/PyTorch 모두 구현 가능, JAX 코드로도 이미 존재함 (논문은 Flax 사용)
✅ 결론 요약
| 항목 | 수치 또는 평가 |
|---|---|
| 파라미터 증가 | 약 1% (token mixer 등) |
| FLOPs 증가 | 약 30% 이내 |
| 메모리 사용량 | 약 70MB (FP32 기준) |
| 구현 공수 | 엔지니어 1 |
| 적용 가능성 | 기존 GPT, LLAMA 등 transformer 계열에 쉽게 확장 가능 |
MELODI는 파라미터 수 증가를 거의 일으키지 않으면서, 메모리와 연산의 사용 효율을 개선하고, long-context capability를 매우 효과적으로 강화할 수 있는 실용적이고 확장 가능한 구조입니다.
Q : 각 컴퍼넌트별로 PyTorch-style 모듈 구현을 만들어줄 수 있겠니?
# MELODI 핵심 컴포넌트 PyTorch-style 모듈 구현
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Optional
# -----------------------------
# 1. Summary Token Mixer (M↑ and M→)
# -----------------------------
class LinearTokenMixer(nn.Module):
def __init__(self, input_tokens: int, output_tokens: int, dim: int):
super().__init__()
self.mixer = nn.Linear(input_tokens, output_tokens, bias=False)
self.proj = nn.Linear(dim, dim) # to map channel-wise
def forward(self, x): # x: [B, T, D]
x = x.transpose(1, 2) # [B, D, T]
x = self.mixer(x) # [B, D, T']
x = x.transpose(1, 2) # [B, T', D]
return self.proj(x)
# -----------------------------
# 2. Gated Cross-Attention Layer
# -----------------------------
class GatedCrossAttention(nn.Module):
def __init__(self, dim, num_heads):
super().__init__()
self.self_attn = nn.MultiheadAttention(dim, num_heads, batch_first=True)
self.cross_attn = nn.MultiheadAttention(dim, num_heads, batch_first=True)
self.alpha = nn.Parameter(torch.ones(num_heads))
def forward(self, x, long_mem_kv):
self_out, _ = self.self_attn(x, x, x)
cross_out, _ = self.cross_attn(x, long_mem_kv, long_mem_kv)
alpha = self.alpha.view(1, 1, -1)
out = alpha * cross_out + (1 - alpha) * self_out
return out
# -----------------------------
# 3. Short-Term Memory Layer
# -----------------------------
class ShortTermLayer(nn.Module):
def __init__(self, dim, num_heads, token_count=512, summary_count=128):
super().__init__()
self.attn = nn.MultiheadAttention(dim, num_heads, batch_first=True)
self.ffn = nn.Sequential(
nn.Linear(dim, dim * 4),
nn.GELU(),
nn.Linear(dim * 4, dim)
)
self.token_mixer_up = LinearTokenMixer(token_count + summary_count, summary_count, dim)
self.token_mixer_right = LinearTokenMixer(token_count + summary_count, summary_count, dim)
def forward(self, x, summary, prev_memory):
input_seq = torch.cat([prev_memory, x], dim=1)
x_out, _ = self.attn(x, input_seq, input_seq)
x_out = x_out + self.ffn(x_out)
combined = torch.cat([x_out, summary], dim=1)
new_summary = self.token_mixer_up(combined)
new_memory = self.token_mixer_right(combined)
return x_out, new_summary, new_memory
# -----------------------------
# 4. Long-Term Memory Update Layer
# -----------------------------
class LongTermMemoryLayer(nn.Module):
def __init__(self, dim, num_heads, token_count=512, summary_count=128, long_tokens=64):
super().__init__()
self.cross_attn = GatedCrossAttention(dim, num_heads)
self.token_mixer_long = LinearTokenMixer(token_count + summary_count, long_tokens, dim)
def forward(self, x, summary, long_mem):
x = self.cross_attn(x, long_mem)
combined = torch.cat([x, summary], dim=1)
long_tokens = self.token_mixer_long(combined)
return x, long_tokens
# -----------------------------
# 5. FIFO-based Long-Term Memory Bank
# -----------------------------
class LongTermMemoryBank:
def __init__(self, max_windows: int):
self.max_windows = max_windows
self.bank = []
def append(self, kv):
self.bank.append(kv)
if len(self.bank) > self.max_windows:
self.bank.pop(0)
def get_memory(self):
if len(self.bank) == 0:
return None
return torch.cat(self.bank, dim=1)
# -----------------------------
# 6. 전체 MELODI 블록 및 Inference 루프
# -----------------------------
class MELODIBlock(nn.Module):
def __init__(self, dim=1024, num_heads=8, num_layers=13, sm_layers=[0,1,2,3,5,6,8,10], lm_layer=7):
super().__init__()
self.dim = dim
self.num_layers = num_layers
self.sm_layers = sm_layers
self.lm_layer = lm_layer
self.layers = nn.ModuleList()
for l in range(num_layers):
if l == lm_layer:
self.layers.append(LongTermMemoryLayer(dim, num_heads))
elif l in sm_layers:
self.layers.append(ShortTermLayer(dim, num_heads))
else:
self.layers.append(nn.TransformerEncoderLayer(d_model=dim, nhead=num_heads, batch_first=True))
self.memory_bank = LongTermMemoryBank(max_windows=128)
def forward(self, x_seq_list):
"""
x_seq_list: List of [B, T, D] segments, one per context window
"""
z_prev = torch.zeros(x_seq_list[0].shape[0], 128, self.dim, device=x_seq_list[0].device) # STM 초기값
u_prev = torch.zeros_like(z_prev) # Summary token 초기값
out_all = []
for x in x_seq_list:
for l, layer in enumerate(self.layers):
if isinstance(layer, ShortTermLayer):
x, u_prev, z_prev = layer(x, u_prev, z_prev)
elif isinstance(layer, LongTermMemoryLayer):
long_mem = self.memory_bank.get_memory()
x, long_token = layer(x, u_prev, long_mem if long_mem is not None else x)
self.memory_bank.append(long_token)
else:
x = layer(x)
out_all.append(x)
return torch.cat(out_all, dim=1) # 전체 output concatQ : 이 논문의 입력데이터와 추론 과정에 대해서 예시를 들어 아주 자세하게 설명해 주겠니? 추가적으로 모델아키텍처의 구성 및 모델을 구성하는 연산과 메모리 요구량 컴퓨팅 요구량 대해서도 설명해줘
아주 좋습니다. 지금까지 정의된 MELODI 아키텍처를 바탕으로, 이 구조가 입력 데이터를 어떻게 처리하고, 추론이 어떻게 동작하며, 연산량/메모리 요구가 어떤지를 구체적인 예시를 들어 설명하겠습니다.
✅ 입력 데이터 예시 및 전처리
입력 예시 (긴 문서)
"In the middle of the night, he found a strange box hidden beneath the floorboards. ..."
→ 길이: 8,192 tokens (예: 긴 소설)전처리
# Assume tokenized to shape [B, 8192]
# Split into 512-token windows → 16개 window
x_windows = torch.split(input_tensor, 512, dim=1) # 각 window: [B, 512, D]이 x_windows는 MELODIBlock에 전달됩니다.
🧠 추론 흐름 (forward logic 예시)
melodi = MELODIBlock(dim=1024, num_heads=8)
output = melodi(x_seq_list=x_windows)내부 처리 순서
ShortTermLayer는 각 window마다 512-token을 처리하면서- 이전 window에서 전달받은
z_{k-1}memory 사용 - summary token을 만들어 다음 layer/다음 window로 전달
- 이전 window에서 전달받은
LongTermMemoryLayer(예: 7번째 layer)에서는- 지금까지 저장된 long-term memory (
m₁:ₖ₋₁)에 대해 cross-attention 수행 - window 전체를 압축해서 64개 long-token 생성 → 메모리 bank에 추가
- 지금까지 저장된 long-term memory (
마지막까지 처리된
x_k는 출력으로 사용됨
🏗️ 모델 아키텍처 구성
| 구성 요소 | 수치 (기준 config) |
|---|---|
| 총 layers | 13 |
| ShortTermLayer | 8 (e.g., layer 0 |
| LongTermLayer | 1 (예: layer 7) |
| dim (hidden size) | 1024 |
| attention heads | 8 |
| context window size | 512 tokens |
| summary token 수 | 128 |
| long token 수 | 64 |
| long mem depth | 128 windows |
💾 메모리 요구량 계산
1. Short-Term Memory
- zₖ: 128 tokens/layer × 8 layers × 1024 dim = 1,048,576 float
- = 4.0MB (FP32) or 2.0MB (FP16)
2. Long-Term Memory
- 64 tokens × 2 (KV) × 1024 dim × 128 windows = 16,777,216 float
- = 64.0MB (FP32) or 32.0MB (FP16)
3. Input/Activation buffer (xₖ: 16 windows)
- 512 × 16 × 1024 = 8,388,608 float = 32MB (FP32)
📌 총 메모리 (FP16 기준, 추론 시):
≈ 2MB (STM) + 32MB (LTM) + 16MB (x buffer) = **50MB 수준**⚙️ 연산량 (FLOPs 기준, 단일 window 처리 기준)
1. ShortTermLayer × 8 layers
- Self-attn: O((512+128)² × 1024) ≈ 0.4G FLOPs/layer
- FFN: 512 × 1024 × 4 × 1024 × 2 ≈ 4.2G FLOPs/layer
- TokenMixer: 2 × 640 × 128 × 1024 ≈ 0.17G FLOPs/layer
→ 총 ≈ ~4.7G × 8 = 37.6 GFLOPs
2. LongTermLayer (1 layer)
- cross-attn: 512 × 8192 × 1024 ≈ 4.3G FLOPs
- token mixer (LTM): ≈ 0.08G FLOPs
→ 총 ≈ ~4.4 GFLOPs
📌 총 추론 연산량 ≈ 42 GFLOPs / window → 16개 window → ≈ 670 GFLOPs (long-context 추론 기준)
✅ 요약 정리
| 항목 | 수치 / 설명 |
|---|---|
| 입력 구조 | [B, 8192, 1024] → 16 window 분할 |
| 연산 구성 | 13-layer Transformer (SM + LM 혼합) |
| 메모리 요구량 (FP16) | 약 50MB |
| 연산량 (추론 전체) | 약 670 GFLOPs |
| 특징 | - SM으로 layer 간 정보 흐름 - LM으로 window 간 정보 압축 전달 - 높은 성능 대비 적은 메모리 |
Q : 이 논문의 한계를 극복하기 위한 방법으로 어떤 연구흐름이 있는지 정리해서 자세하게 설명해 줘
MELODI는 뛰어난 효율과 성능을 보여주는 구조이지만, 논문에서도 일부 한계점을 명시하고 있습니다. 여기에 기반하여, 해당 한계를 극복하기 위한 연구 흐름 및 아이디어를 다음과 같이 정리해 드리겠습니다:
✅ MELODI의 핵심 한계
| 구분 | 설명 |
|---|---|
| 1. Pretrained 모델 적용 불가 | MELODI는 학습을 처음부터 진행해야 하며, 기존 사전학습 모델(GPT 등)에 직접 적용이 어렵다. |
| 2. Fixed compression ratio | SM/LM에서 사용하는 token 수가 고정되어 있어, 다양한 문서 길이나 도메인에 유연하게 대응하지 못함. |
| 3. 정보 손실 가능성 | 요약 기반 메모리는 압축 과정에서 중요 정보를 누락할 위험이 있다. |
| 4. 순차 추론 구조 | window 간 순차적 추론이 필요해, parallelism이 제한된다. |
🔍 한계 극복을 위한 연구 흐름
1. 🔄 Pretrained 모델에 MELODI memory 삽입
연구 흐름: 기존 사전학습된 모델(GPT, LLaMA)에 MELODI-style memory module을 삽입하는 방식 (plug-and-play)
방법: LoRA, Adapter, QLoRA 등과 결합해 fine-tuning
예시:
- 🔸Memory-Augmented Fine-tuning
- 🔸Adapter with Memory Bank
- 🔸Flash-Memory Injection (streamable memory)
➡️ 적용성 강화 + 파라미터 효율성 확보
2. 🧠 Adaptive Compression Memory (압축 적응화)
연구 흐름: token importance score를 기반으로 요약 비율을 동적으로 조절
관련 연구:
- 🔸AutoCompressor (Chevalier et al. 2023): attention-based token compression
- 🔸ICAE (2024): adaptive context encoder with LoRA
가능한 확장:
- 정보량 많은 window는 더 많은 long-token 할당
- summary token 수를 layer depth나 attention entropy에 따라 변경
➡️ 정보 손실 최소화 + 고효율 요약
3. 🔁 Recursive Memory Compression
개념: LM을 단일층이 아닌 다층으로 구성하고, 오래된 memory는 재압축 (recompress) → compact KV 유지
영감: Compressive Transformer (Rae et al. 2019)
적용 방법:
- 일정 window 이상 오래된 memory → 다시 한 번 token mixer에 입력하여 재요약
- 기존 FIFO → multi-tier cache 구조
➡️ long-context 유지 능력 향상 + memory 폭증 억제
4. ⚡ 비순차적 memory 접근 지원
문제: MELODI는 window 순차 처리 → parallelization 어려움
해결 방향:
- long-term memory는 read-only + cross-attn만 수행하도록 만들면 여러 window에서 병렬 접근 가능
- memory indexing을 positional RoPE 기반으로 정규화하여 비순차 window에도 대응 가능
➡️ 멀티-GPU 또는 분산 추론 효율 극대화
5. 🌐 Multi-modal 확장
동기: MELODI 구조는 modality-independent (압축/메모리 방식은 text 외에도 적용 가능)
적용 가능 영역:
- 영상/음성의 temporal compression
- multi-modal summary token (예: vision-text)
➡️ GEMINI-style 모델에서 효율적 long-memory 구성 가능
🧩 종합 정리: 연구 방향 매핑
| 한계 | 극복 연구 흐름 | 대표 아이디어 |
|---|---|---|
| Pretrained 불가 | Memory-finetune, LoRA | memory-injection |
| 고정 압축비 | Adaptive compression | token importance → compression ratio |
| 정보 손실 | Multi-pass summarization | 재요약 / 정보 선택 |
| 순차적 구조 | Memory-as-Cache 방식 | long-memory 병렬 접근 |
| 도메인 고정 | Multi-modal 확장 | 요약 방식 일반화 |
Q : MELODI의 short-term memory와 long-term memory는 각각 어떤 방식으로 정보를 압축하고 전달하며, 이 구조가 기존 memory-augmented transformer들과 비교해 어떤 이점을 제공하는가?
아주 좋은 질문입니다. 아래에 MELODI의 short-term memory (STM), **long-term memory (LTM)**가 어떻게 정보를 압축하고 전달하는지 그리고 기존 memory-augmented transformer와의 비교를 정리해드립니다.
✅ MELODI의 Memory 구조와 동작 방식
1. Short-Term Memory (STM): Layer-wise recurrent compression
목적: 현재 window 내 정보 + 이전 window 요약 정보를 처리
구현 방식:
각 context window
xₖ를 여러 ShortTermLayer에 통과시키며 반복 압축각 layer에서는:
- context token
xₖ, summary tokenuₖ, 이전 memory tokenzₖ₋₁을 입력으로 사용 - attention + FFN 후,
xₖ′생성 - summary token과 함께 linear token mixer를 통해 다음 layer용
uₖ, 다음 window용zₖ생성
- context token
정보 흐름:
- layer 간:
uₖ(summary token) - window 간:
zₖ(compressed STM token)
- layer 간:
👉 이 구조는 Transformer 내부에 LSTM처럼 layer-recurrent 흐름을 만든다고 볼 수 있음
2. Long-Term Memory (LTM): Mid-layer compression + FIFO stacking
목적: 과거 여러 window의 전체 요약 정보를 장기적으로 유지
구현 방식:
- 중간 layer (예: 7층)에서, 현재
xₖ,uₖ를 long-term memory와 cross-attention - self-attn과 cross-attn을
αgating으로 합성 - 이어서 token mixer를 통해 512-token window를 64개 long-token으로 압축
- 이 KV쌍을
mₖ로 저장, memory queue (m₁:ₖ)에 append
- 중간 layer (예: 7층)에서, 현재
👉 정보는 KV 형태로 저장되며, 다음 window 처리 시 cross-attention 대상이 됨
📊 기존 memory-augmented 모델과의 비교
| 항목 | Memorizing Transformer | MELODI |
|---|---|---|
| memory 저장 방식 | 단일 layer에서 모든 token의 KV 저장 | 중간 layer에서 압축된 KV 저장 |
| 단기 문맥 유지 | 없음 (직접 token attention) | STM 사용으로 연속성 보존 |
| memory 용량 | 매우 큼 (dense KV 저장) | 8~10배 적음 (64-token 수준) |
| 정보 흐름 | 단일 방향 (context → memory) | 계층적 흐름 (SM + LM) |
| attention 방식 | cross-attn (top-k 또는 dense) | gated self + cross-attn |
| 요약 방식 | 없음 (raw token 저장) | token mixer 기반 요약/압축 |
🎯 MELODI의 구조적 이점 요약
메모리 효율성 압축된 memory token (e.g., 64개)만 저장 → MT 대비 최대 8배 감소
장단기 문맥 결합 STM: 직전 window와 smooth한 연결 LTM: 전체 history 요약 저장 → local + global 문맥 모두 보존
연산 최적화 cross-attn은 단 1 layer에서만 수행, top-k pruning 없이도 낮은 cost
학습된 memory 제어 (gating) self vs. cross attention을 α로 조절 → 메모리 의존도 학습 가능
결론적으로, MELODI는 기존 memory transformer들의 memory 폭증 문제를 해결하면서도, 정보 보존과 추론 성능을 양립한 계층적 메모리 구조를 설계한 것이 가장 큰 강점입니다.
더 궁금하신 점 있으실까요? 또는 이 구조를 활용한 downstream task 적용 방식이 궁금하신가요?
Q : 논문에서 제안하는 hierarchical memory compression 방식이 long-context language modeling의 성능 향상에 어떤 기여를 했는지, ablation 결과를 통해 어떻게 검증되었는가?
논문에서 제안하는 Hierarchical Memory Compression은 MELODI의 핵심 기여로, **short-term memory (STM)**과 **long-term memory (LTM)**를 계층적으로 결합함으로써 long-context language modeling의 성능을 높였습니다. 이 구조가 실제로 어떻게 성능 향상에 기여했는지는 Ablation Study를 통해 명확히 검증되었습니다.
아래에 구조적 이해와 ablation 결과 기반의 분석을 정리해드립니다.
✅ Hierarchical Memory Compression이란?
Short-Term Memory (STM):
- context window 내 정보를 여러 layer를 통해 반복적으로 압축
- 이전 window의 memory token
z_{k-1}와 summary tokenu_{k-1}활용 - 로컬 문맥 유지에 효과적
Long-Term Memory (LTM):
- 한 중간 layer에서 context window 전체를 요약 → 64개 token으로 압축
- 과거 window들의 압축된 KV를 FIFO queue에 저장
- 전역 문맥 유지에 효과적
요약: → STM은 최근 문맥을 세밀하게 보존, LTM은 먼 과거를 요약해 기억 → 이 둘을 계층적으로 결합하여 short+long dependency 동시 처리
🧪 Ablation 실험으로 확인된 기여
1. STM + LTM 조합의 성능 향상 (Fig. 4)
실험 설정: PG-19 (T5 vocab) 기준
조건:
- 다양한 short memory (
S) - 다양한 long memory (
L) 크기 - 총 perplexity 비교
- 다양한 short memory (
결과 요약:
| 구조 | Perplexity (PG-19) |
|---|---|
| STM only (S192+L0) | 11.0+ (높음) |
| LTM only (S0+L64) | 11.2+ (높음) |
| STM + LTM (S128+L64) | 10.44 (최저) |
➡️ STM과 LTM은 상호보완적이며, 둘을 함께 써야 성능 최적화
2. LTM coverage가 성능에 미치는 영향 (Fig. 5)
- 고정된 L = 64 long-token, S = 128 short-token
- LTM이 커버하는 window 수: 2 → 128까지 실험
결과 요약:
- 2~4 window만 포함한 LTM은 성능 거의 변화 없음
- 32 window 이상 포함한 경우부터 PPL 급격히 개선
- 128 window 이상에서는 성능 개선 정체
➡️ STM은 최근 몇 window까지만 효과적, 멀어진 문맥은 LTM이 필요
3. Summary Branching 기법의 영향 (Table 4)
| 구조 | PPL (ST only) | PPL (ST+LT) |
|---|---|---|
| without branching | 11.68 | 11.24 |
| with branching | 11.39 | 10.95 |
➡️ layer 간 summary token 흐름을 강화한 것이 성능 향상에 직접 기여함을 보여줌
📌 정리: 성능 향상에 기여한 핵심 포인트
| 기법 | 기여 |
|---|---|
| STM (multi-layer compression) | 최근 문맥 정보 세밀하게 유지 → short-range dependency 강화 |
| LTM (window-level compression) | 오래된 문맥을 간결하게 보존 → long-range dependency 유지 |
| Summary token + branching | 정보 흐름 개선 → 압축 효율 및 계층간 정보 전달력 증가 |
| Gated cross-attn | LTM 의존도 조절 가능 → 적절한 memory usage 학습 가능 |
🎯 결론
Ablation 결과는 MELODI의 hierarchical memory 구조가 단순 memory stacking 방식보다 훨씬 효율적이며, STM과 LTM의 계층적 결합이 long-context 이해 능력 향상에 핵심적인 기여를 한다는 것을 실증적으로 보여줍니다.
Q : MELODI 구조가 갖는 한계(예: pretrained 모델 적용 어려움, 순차적 처리 등)는 실제 응용에서 어떤 제약을 만들며, 이를 보완하기 위한 기술적 확장 가능성은 어떤 것이 있을까?
MELODI는 효율적이고 강력한 long-context 처리 능력을 보여주지만, 몇 가지 구조적 한계가 실제 응용에 제약을 줄 수 있습니다. 아래에 MELODI의 구조적 한계, 응용상의 제약, 그리고 이를 보완할 수 있는 기술적 확장 가능성을 정리해드립니다.
✅ MELODI 구조의 주요 한계와 실제 제약
1. 사전학습(pretrained) 모델 적용 어려움
문제: MELODI는 Transformer 구조를 바꾼 구조이기 때문에 기존 GPT, LLaMA 등의 pretrained weight를 직접 사용할 수 없음
실제 제약:
- 기존 대규모 사전학습 자원을 활용할 수 없어 from scratch training 필요
- 비용, 데이터 확보, 성능 재현 측면에서 현실적인 장벽 존재
2. 순차적 처리 (window-by-window)
문제: context window를 순서대로 처리하면서 memory를 갱신하는 구조 → 병렬성 제한
실제 제약:
- batch-level parallelism 불가 → 추론 latency 증가
- GPU 다중처리나 분산추론에 불리 → inference throughput 낮음
3. 메모리 압축의 정보 손실 가능성
문제: long-term memory는 summary token을 통해 압축 저장
- → 모든 중요한 정보가 보존된다는 보장은 없음
실제 제약:
- 일부 downstream task (예: QA, reasoning)에서는 치명적 정보 유실 가능
- 특정 window의 핵심 내용이 추론 시 누락될 위험
🔧 기술적 확장 가능성 및 보완 방안
1. Pretrained 모델과의 호환을 위한 Adapter-based 삽입
접근법: 기존 GPT 등의 사전학습 모델에 MELODI memory block을 LoRA, Adapter 형태로 삽입
예시 아이디어:
MELODI-Attention→ 기존 self-attn 후 cross-attn to memory 추가- 기존 weight freezing + memory block만 학습
장점:
- 사전학습 weight 활용 가능
- few-shot tuning 가능
2. 비순차적 memory 접근 구조로 parallelism 확보
접근법:
- Long-term memory를 KV cache처럼 read-only 구조로 구성
- 여러 window를 병렬적으로 long memory에 cross-attn 수행 가능하게 변경
예시:
- “FlashMemory-style” 접근
- Routing index와 positional RoPE 보정 활용
장점:
- window 간 병렬 처리 가능 → GPU 효율 개선
3. 정보 손실 최소화를 위한 Adaptive Memory Compression
접근법:
- token importance 기반으로 summary token 비율을 동적으로 조정
- 또는 retrieval 기반 memory reinforcement (RAG hybrid)
기술 흐름 예시:
- AutoCompressor (Chevalier et al. 2023)
- Gisting (Mu et al. 2024)
장점:
- 압축 손실을 최소화 → 고정 summary token 구조보다 정밀
4. Memory 재활용 구조 추가 (Compressive Memory)
접근법:
- 오래된 long-term memory를 재요약하여 compact하게 보관
- Compressive Transformer와 유사한 multi-tier memory stack 구성
장점:
- memory 용량 제한 극복 + 정보 유지
5. Multi-modal 확장성 확보
접근법:
- MELODI의 memory block을 vision/audio encoder 뒤에 연결
- multi-modal token도 memory token처럼 처리
장점:
- Gemini, Flamingo 등 multi-modal long context 모델로 확장 가능
📌 결론 요약
| 한계 | 응용 제약 | 보완 방안 |
|---|---|---|
| pretrained 적용 어려움 | 기존 weight 재사용 불가 | memory block → adapter/LoRA화 |
| 순차 처리 구조 | GPU 병렬성 저하 | LTM을 read-only cross-attn으로 구조화 |
| memory 정보 손실 | 추론 정보 유실 가능성 | token 중요도 기반 adaptive compression |
| memory 폭증 | 긴 문서에서 메모리 한계 | compressive memory or hybrid routing |
| modality 한정 | text 전용 구조 | multi-modal memory 확장 가능 |
댓글