
그래서 많은 시행착오를 끝에 알아낸것이 다음과 같은 최적화를 추가하면 수행이 된것이다.
아래는 행렬 연산의 예시이며 loop unroll and jam 이 수행되어야한다.
#define N 256
#define size 1024
int A[size][size];
int B[size][size];
int C[size][size];
void matmul() {
int i,j,k;
for (i=0; i < N; i++)
for (j=0; j < N; j++)
for (k=0; k < N; k++)
C[i][j] += A[k][i] * B[j][k];
}clang -Xclang -disable-O0-optnone -emit-llvm matmul.c -S
opt -stats -debug -loop-unroll-and-jam -allow-unroll-and-jam -unroll-and-jam-count=2 matmul.ll위처럼 해도 최적화가 수행안되는데 이걸로 삽질을 많이했다.
아래 pass를 추가하면 unroll and jam이 수행된다.
-mem2reg -simplifycfg -loop-rotate -instcombine
그리고 이걸하면서 cfg를 확인할 일이 있어 다음옵션을 유용하게 이용하였다.
opt -view-cfg matmul.ll 을 하면 다음과 같은 cfg가 나오며 xdot을 설치해야 볼수있다.(우분투에서는 sudo apt-get install xdot로 설치가능하다)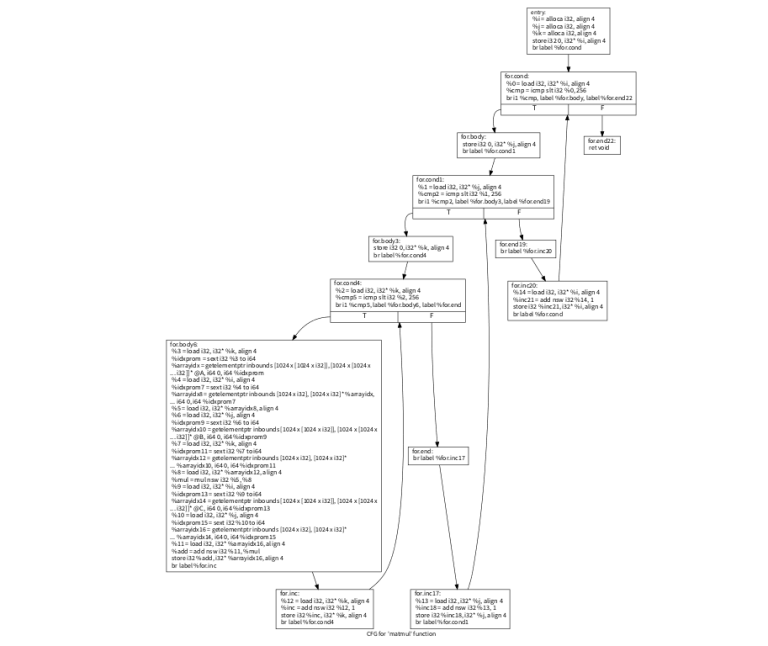
프로젝트의 결론 중 하나가 loop-unroll and jam은 결국 아래 다이어 그램에서 표기된 target independent 한 simple loop opt의 하나이므로 이것 하나의 수행 여부를 판별하는 것이 전체적인 최적화 pass의 성능 여부에 생각보다 큰 영향을 미치지 못한다는 것이다.(유감..)
아마 NAS에서 연구되는 방법을 사용하여 phase ordering 조금 더 섬세하게 하면 성능향상이 있을 것 으로 예상이 된다.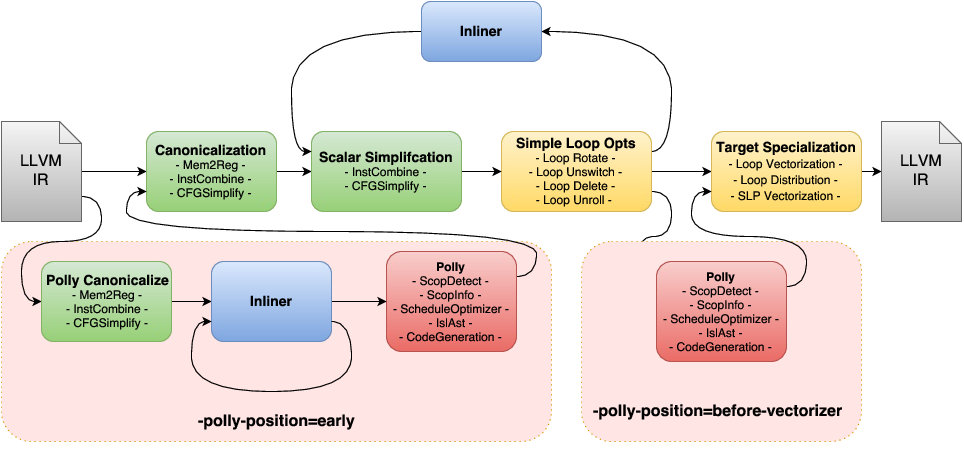
댓글